
Segment Anything Model (SAM):图像分割领域的革命性AI模型
Segment Anything Model (SAM)是由Meta AI研发的一款具有开创性意义的人工智能模型,专注于图像分割任务,为计算机视觉领域带来了全新的突破。
一、模型概述
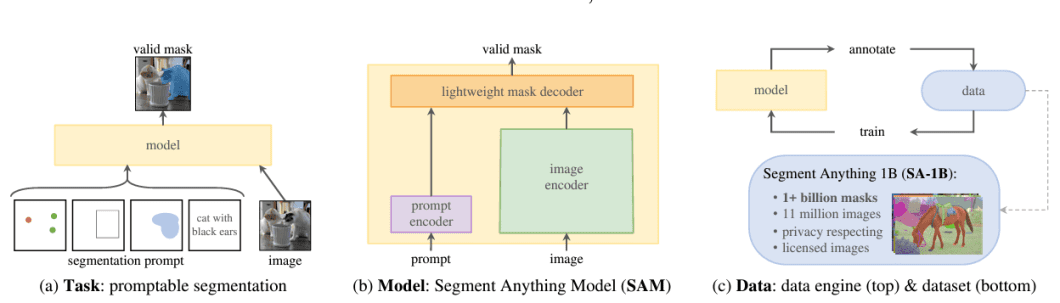
SAM旨在解决图像分割中“分割任何对象”的难题,它采用了创新性的提示式分割系统设计,具备零样本泛化能力,即使面对从未见过的对象和图像,也无需额外训练即可进行分割操作。这一特性使得SAM在处理各种复杂图像时展现出强大的适应性和灵活性,极大地拓宽了图像分割技术的应用范围。
二、核心特点与功能
(一)多样化的输入提示
1. 灵活的交互方式:SAM支持多种输入提示方式,如通过在图像上指定交互式点和框,用户可以轻松地告诉模型需要分割的对象或区域。这种直观的交互模式使用户能够根据自己的需求精确地定义分割任务,无论是突出显示前景对象、分离特定区域还是进行复杂的多对象分割,都能够通过简单的点选和框选操作实现。
2. 自动全图分割:除了交互式提示,SAM还能够自动分割图像中的所有对象。这一功能在处理大规模图像数据集或需要快速获取图像中所有对象信息的场景中尤为有用,例如图像分析、场景理解等领域,为后续的进一步处理提供了全面的基础数据。
3. 处理模糊提示:对于模糊或不明确的提示,SAM能够生成多个有效的掩码。这体现了模型对图像内容的深度理解和强大的推理能力,它可以根据图像的上下文和语义信息,推测出多种可能的分割结果,为用户提供更多的选择和参考,从而更好地满足复杂的实际应用需求。
(二)强大的零样本泛化能力
SAM通过学习获得了对对象的一般性理解,这种理解使其能够在没有见过特定对象或图像的情况下,准确地进行分割。这一能力基于Meta AI在模型训练过程中所采用的大规模数据和先进算法,使得SAM可以将在训练数据中学到的知识和模式应用到新的、未知的场景中,显著减少了对每个新任务进行特定训练的需求,提高了模型的通用性和效率。
(三)灵活的系统集成与可扩展输出
1. 与其他系统的集成潜力:SAM的提示式设计使其能够与其他系统进行灵活集成。例如,在未来的增强现实(AR)/虚拟现实(VR)应用中,它可以接收来自头戴式设备的用户凝视信息,从而实现基于用户视线的对象选择和分割。此外,来自对象检测器的边界框提示可以用于实现文本到对象的分割,进一步拓展了模型在多模态交互和智能视觉处理中的应用可能性。
2. 丰富的输出应用场景:SAM生成的掩码输出具有广泛的可扩展性,可作为其他AI系统的输入。例如,在视频处理中,对象掩码可以用于跟踪视频中的对象,实现目标跟踪和行为分析;在图像编辑应用中,可用于精确的图像裁剪、合成和特效添加;还可以将掩码提升到3D空间,为3D建模和计算机图形学提供基础数据,或者用于创意任务如拼贴艺术创作等,为视觉创意和设计领域带来新的灵感和工具。
三、模型训练与技术细节
(一)数据驱动的训练方法
SAM的卓越性能得益于其在数百万张图像和超过10亿个掩码上的训练,这些数据是通过一种模型循环的“数据引擎”收集而来。研究人员利用SAM及其生成的数据,以交互方式对图像进行标注,并不断更新模型。通过多次重复这一循环过程,模型和数据集的质量都得到了显著提升,从而为SAM的强大功能奠定了坚实的基础。
(二)高效灵活的模型架构
1. 图像编码器:SAM采用了ViT - H图像编码器,对每张图像仅需运行一次,即可输出图像的嵌入表示。该编码器具有632M个参数,在NVIDIA A100 GPU上,处理一张图像大约需要0.15秒,其高效的设计为整个模型的性能提供了有力支持。
2. 提示编码器与掩码解码器:提示编码器负责将用户输入的提示(如点击、框选等)转换为嵌入表示,掩码解码器则基于图像嵌入和提示嵌入来预测对象掩码。这两个部分相对较轻量,总共仅有4M个参数,并且能够在浏览器中使用多线程SIMD执行,在CPU上每个提示的处理时间约为50毫秒,使得模型能够在保证性能的同时实现快速的交互响应。
(三)多平台支持
SAM在技术实现上具有良好的平台兼容性。图像编码器使用PyTorch实现,为了实现高效推理,需要GPU支持。而提示编码器和掩码解码器既可以直接使用PyTorch运行,也可以转换为ONNX格式,从而在支持ONNX运行时的各种CPU或GPU平台上高效运行,这为不同硬件环境下的用户提供了使用SAM的可能性,促进了模型的广泛应用。
Segment Anything Model (SAM)凭借其创新的技术设计、强大的功能特性以及高效的训练和运行机制,在图像分割和计算机视觉领域树立了新的标杆,为众多相关领域的发展提供了强有力的技术支持,有望在未来的智能视觉应用中发挥更加重要的作用。
开源的搭建机器学习模型UI界面的Python库